一、前人的工作与问题
目标检测需要一组预定义好的anchor box,存在一些缺点
- 对物体大小以及长宽比的变化比较敏感(确实,对于同一个物体,根据相机距离远近的不同,成像大小也不同,需要不同的框去包围;同时对于形态的变化也需要进行相应调整;anchor box的大小应该是能自适应调整的;什么特征会与anchor box大小相关?)
- anchor-based detector需要密集地将anchor box放置在图像上,而绝大多数都是负样本,一方面计算量太大,另一方面正负样本的比例失衡,不利于模型的训练
希望设计FCN的框架去生成anchor-free的detector
二、做法
per-pixel prediction + multi-level prediction+’center-ness’branch
1.Fully Concolutional One-Stage Object Detecor
训练数据:输入image的anchor box由五元向量构成:四个anchor坐标+一个class坐标。将每个位置的pixel的信息作为training samples。对于处于(x,y)的像素,如果它落于任何ground-truth anchor box中且类别正是anchor box所框中物体的类别,则认为它是正样本;否则是负样本,类别为0(用于描述背景的类别);而如果落在多个box中则认为是一个ambiguous sample.
regression target:对于每个位置的像素,预测四元距离向量,即与bounding box四条边的距离
network outputs:同regression target再,加上一个class vector。class vector是一个C维向量,利用的是C个二元分类器而不是一个多级分类器。
优势:在训练过程中可以充分利用foreground samples.
网络架构与Loss function:

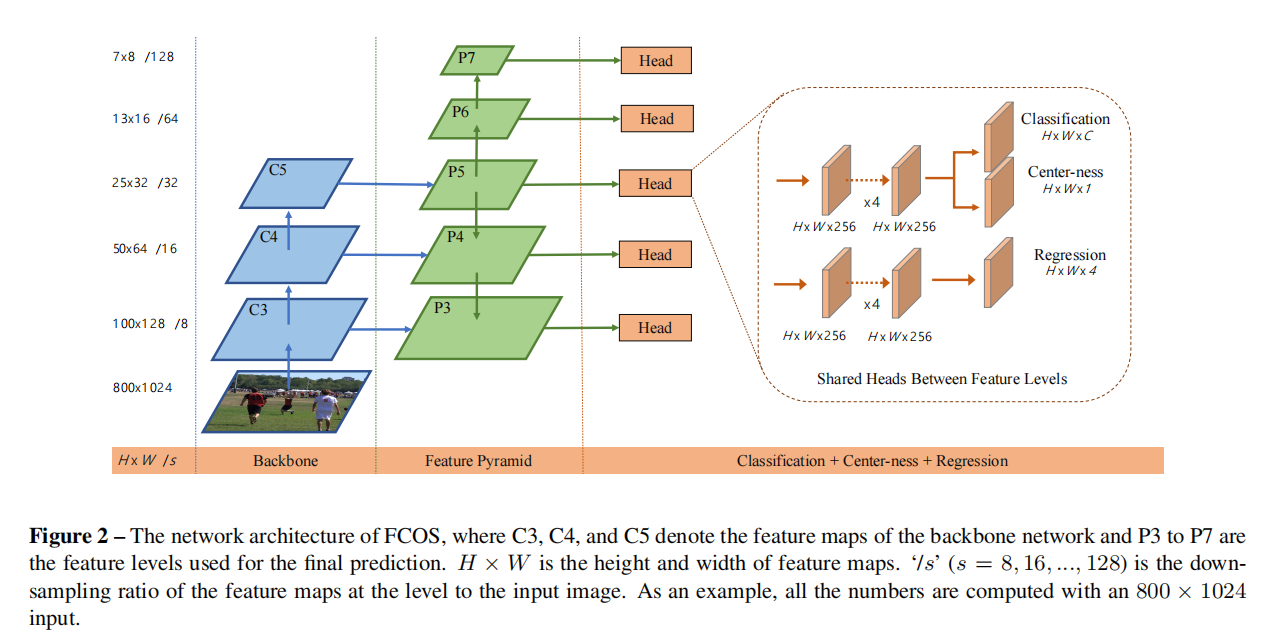
2.Multi-level Prediction with FPN
两个可能存在的问题:
- 用CNN处理具有大步长的feature map可能带来较低的BPR
- ground-truth box的重叠可能会模棱两可,该位置的像素对应哪个box呢?
做法:首先获取不同大小的feature maps{P3,P4,P5,P6,P7},在这些feature maps上做detect得到很多regression targets,对这些detect targets限制大小。最终如果一个位置的像素仍与多个box匹配,则选择面积最小的box作为结果输出。
细节:heads模块在不同feature levels中共享,优点是detector更高效且提升性能;但是由于不同feature levels得到的box的大小具有不同的范围,所以不太合理,解决方法是使用自适应的指数函数exp(six)来调整feature level Pi.
3.Center-ness for FCOS
**问题:**大量低质量的bounding box被远离物体的中心的点产生
做法:增加了一个single branch来预测一个点的”center-ness”,”center-ness”描述了从该点到该点属于的物体中心的归一化距离。center-ness 在0到1之间且用BCE训练,该loss在loss function中体现。在测试过程中,class由初始预测class与center-ness相乘得到,从而可能远离物体中心的属于物体的点在NMS步骤中被滤除。
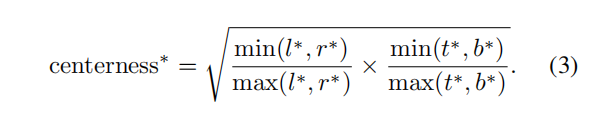
三、思考
1.anchor-box free的想法很厉害,将image-level的问题用pixel-level解决,对每个位置上的像素进行预测bounding box与class;后续的设计都从而展开;多级预测的思想也很厉害,在降采样的图像金字塔上分别做预测,能解决ambiguous sample的问题,也能增加预测结果的鲁棒性。
2.我的一些想法
关于bounding box:
是否需要绘制bounding box?bounding box依赖于该物体像素的分布,如果能准确预测每点像素的值,是否Bounding box也可以从这些像素的位置中推导得到(取到上下、左右边界即可),也即图像语义分割+类别标注+bounding box绘制能否达到同样效果?这样也能直接解决multi bounding box的问题。但是感觉对单点做分类好难。
能不能再加一个post-process:根据一个限制条件:同一物体的点的regression targets在邻域内应当是连续的,不能出现大的跳变来提高bounding box的准确性。或者在loss function中体现?
关于点:
单独的点是没有任何意义的,只有将点放在上下文中它才能构成物体或者背景,但在从实物到图像的采样过程中,点的像素值具有噪声也受光照等因素影响。CNN的卷积操作、池化操作都能起扩大感受野的作用,将孤立的点与邻域的点联系起来并提取特征,从关联性的角度看,self-attention能否起到类似的作用?不需要对整张图片做self-attention,能不能用local self-attention代替卷积?或者用self-attention与CNN相结合?
以及局部特征的提取?卷积运算简单且高效,但是固定窗口是否略显僵硬?虽然可以用不同大小的卷积进行操作。而且特征的体现还是以像素值进行表征,是否过于简单?