一、背景与构想
1.背景
三类分割任务:semantic、instance、panoptic segmentations,虽然有潜在的关联性,但此前的解决方案各不相同(specialized).
2.构想
作者希望能提供一个统一的架构解决这些segmentation的问题,方法是利用learnable kernels,每个kernel为一个object或stuff生成一个mask。
- 首先是一个统一的架构,用于解决联系三类segmentation问题
- 随机初始化一系列卷积核,在不同任务中学习不同参数。semantic categories–>>sementic kernels;instance identies–>>instance kernels;sementic kernels+instance kernels可以解决panpotic segmentations
- bipartite matching策略,最终建立起instance和kernel的映射关系;此外可以做到NMS-free和Box-free,有利于实时性。
二、前人的工作与问题
1.semantic segmentation
很多研究者将这个视为一个dense classification的问题,很多方法基于FCN。在FCN的基础上,许多研究者研究更好的特征表示方法,通过做dilated convolution、pyramid pooling、context representations、attention mechanisms、transformer来提升性能
2.Instance Segmentation
两种代表框架:”top-down”与”bottom-up”
top-down: 先精确探测bounding boxes,再对每个box生成一个mask.
bottom-up: 先做semantic segmentation再将同物体像素聚合成一个instance
整体而言,top-down的效果更好,但是两者都存在的问题是:Instance segmentation任务都被分成的两个步骤解决,K-net通过将kernel与预测mask建立对应关系,可以同时做segmentation和instance separation.
3.Panoptic Segmantation
如何将sementic segmentation与instance segmentation结合在一起地问题。
可以在实例分割的基础上增加一个语义分割的branch;也可以在语义分割的基础上做pixel grouping
(待补充)
4.Dynamic Kernels
很多工作对卷积核的利用都是静态的,agnostic to the inputs。泛化能力不强,之前关于dynamic kernels的研究专注于提升模型的灵活性,增加感受野等。
三、做法
1.K-Net
首先定义’meaningful group’:每张图片对应输出一个meaningful group,在不同的分割任务中有着不同的meaningful group,可以将meaningful group理解为一个样本空间。在semantic segmantation中,这个group包含所有可能的class;在instance segmentation中,这个group是一张图片可能包含的instance的集合;在panoptic segmentation中,这个group包含所有objects和stuff。
同时每张图片对应的meaningful group是一个可数有限集,不妨令group包含的最大元素数是N。K-Net将三类group统一起来,使用N(预定义参数)个kernel,每个kernel对应输出group的一个元素,要么是一个potential instance,要么是一个 semantic class。
做法:
$$
feature\ map: F\in R^{B\times C\times H\times W} \
N\ kernels: K\in R^{N\times C} \
segmentation\ prediction\ M\in R^{B\times N\times H\times W} \
M\ =\ \sigma(K\times F)
$$
输出B张图像,经过深度神经网络生成fearure maps F,再利用N个kernels与F做卷积,经过激活函数输出prediction map M。每一张image,M输出N个group元素,每个group元素是一个HXW的张量
优势:
同时做segmantation与instance detection,做法简便且迅速
但是,如何更新kernel的参数?如何定义loss function?
2.Group-Aware Kernels
解决参数更新的问题
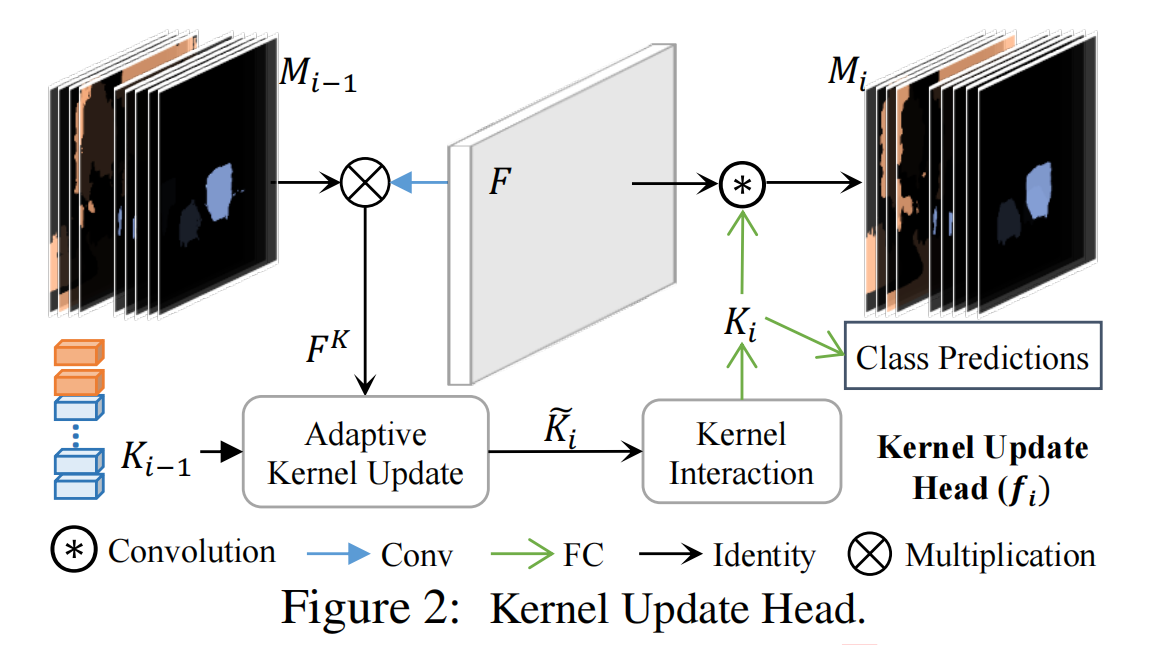
三个步骤:group feature assembling + adaptive kernel update + kernel interaction
迭代过程:
- 使用prediction map Mi-1装配得到group feature FK,FK表征每个group元素的特征与差异性
- 使用FK更新kernel Ki-1
- kernel相互交互综合建立起图像内容
- 使用得到的Ki做卷积得到prediction map Mi
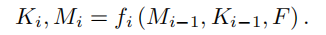
框架
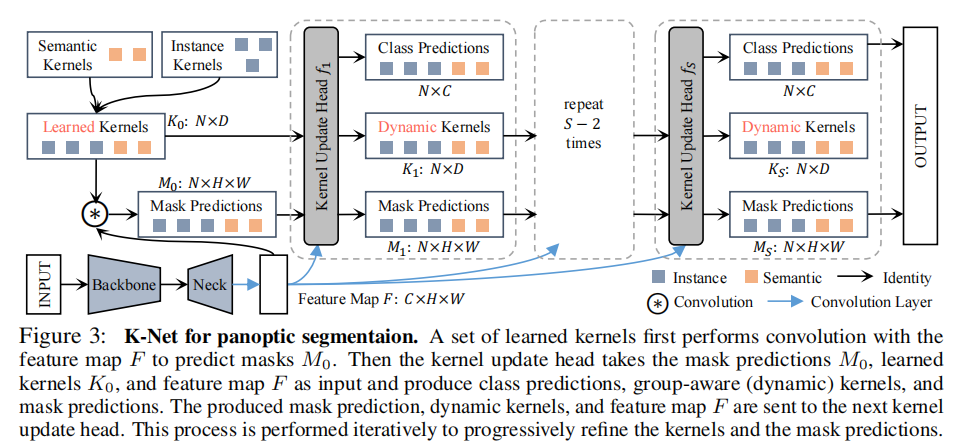
(具体class predictions与mask predictions是怎么完成的?是耦合在一起,直接通过Kernels得到吗?还是又训练了一个分类器来对Mask做prediction?不对,按照论文思路是同时产生的,直接根据group feature吗?怎么同时产生?)
2.1 Group Feature Assembling
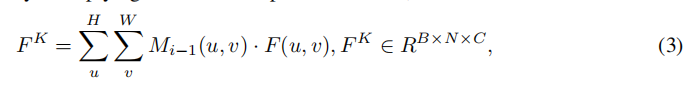
2.2 Adaptive Feature Update
prediction Map M的维度是NXHXW,每个Group元素的规模是一张图像的大小,所以可能会不可避免的产生一些噪声。为了减少噪声的影响,使用自适应的kernel更新策略
首先对FK与Ki-1做element-wise multiplication
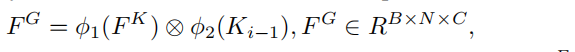
两个函数表示线性变换
随后Head学习到两个门限GK和GF,并用他们和前面的FK与Ki-1一同更新K
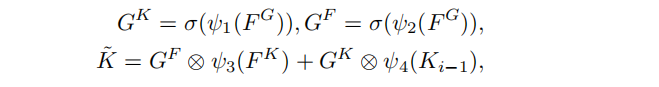
四个函数表示不同的fully connected(FC)layers followed by LayerNorm(LN),激活函数是Sigmoid
得到的K用于kernel interaction
gate functionGK和GF的角色类似于transformer中的self-attention机制,形式也非常相似。
2.3 Kernel Interaction
目的是为了使每个kernel能知道其他group的信息
使用Multi-Head Attention followed by a Feed-Forward Neural Network,输出就是新的Ki,并用来生成新的mask prediction Mi
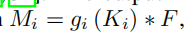
gi是FC-LN-ReLU layer followed by an FC layer.
ki同时也会用于intance segmentation和panoptic segmentation中的类别预测
3.Training Instance Kernels
1.class、instance number与kernel的匹配问题
semantic kernel:固定每个kernel对应的semantic class
instance kernel:使用bipartite matching作为map策略(不懂)
2.损失函数
$$
L_K = \lambda_{cls}\times L_{cls}+\lambda_{ce}\times L_{ce}+\lambda_{dice}\times L_{dice}
$$
Lcls由classification产生,Ldice和Lce是分割问题的CrossEntropy loss和Dice Loss。
作者使用Dice的原因是:当instances只占据图片的很小一部分的时候,交叉熵损失不足以用于处理如此不平衡的学习目标。
3.Mask-based Hungarian Assignment
用于target分配,在predicted instance masks与ground-truth instances之间建立起一一映射。