一、任务概要与方法简述
1.概要
利用多相机多视角拍摄的图像做3D目标检测,也需要输出3D空间中的信息
目前很多工作都是直接使用2D目标检测问题的框架,从单目图像中估计3D bounding boxes,而没有考虑到3D场景结构或传感器信息。所以这些方法需要使用post-process来结合不同相机图像预测的bounding box以及剔除redundant boxes。
或者根据2D的特征信息利用depth prediction network做3D目标检测,或者做3D重建去达到类似激光雷达传感器获得的作用,随后再用3D信息做目标检测。这类方法的问题主要是重建3D场景或者恢复深度信息时的误差。
2.方法
- starts from a sparse set of object priors, shared across the dataset and learned end-to-end
- Back-project a set of reference points decoded from object priors to each camera and fetch the corresponding image features extracted by a ResNet backbone
- The features collected from the image features of the reference points then interact with each other through a multi-head self-attention layer
- After a series of self-attention layers, we read off bounding box parameters from every layer and use a set-to-set loss inspired by DETR to evaluate performance
二、做法细节
输入:K个相机采样的图像,相机参数,透视矩阵,ground-truth bounding boxes B与对应的categorical labels.Bounding box包含参数有:position,size,heading angle and velocity in birds-eye view(BEV)
输出:预测包含上述参数的bounding box与类别
1.特征提取
使用ResNet与FPN从输出图像中提取得到四组features, F1,F2,F3,F4,每一组特征都是不同level的特征用于提供探测不同大小的物体所需要的的信息
2.Detection Head
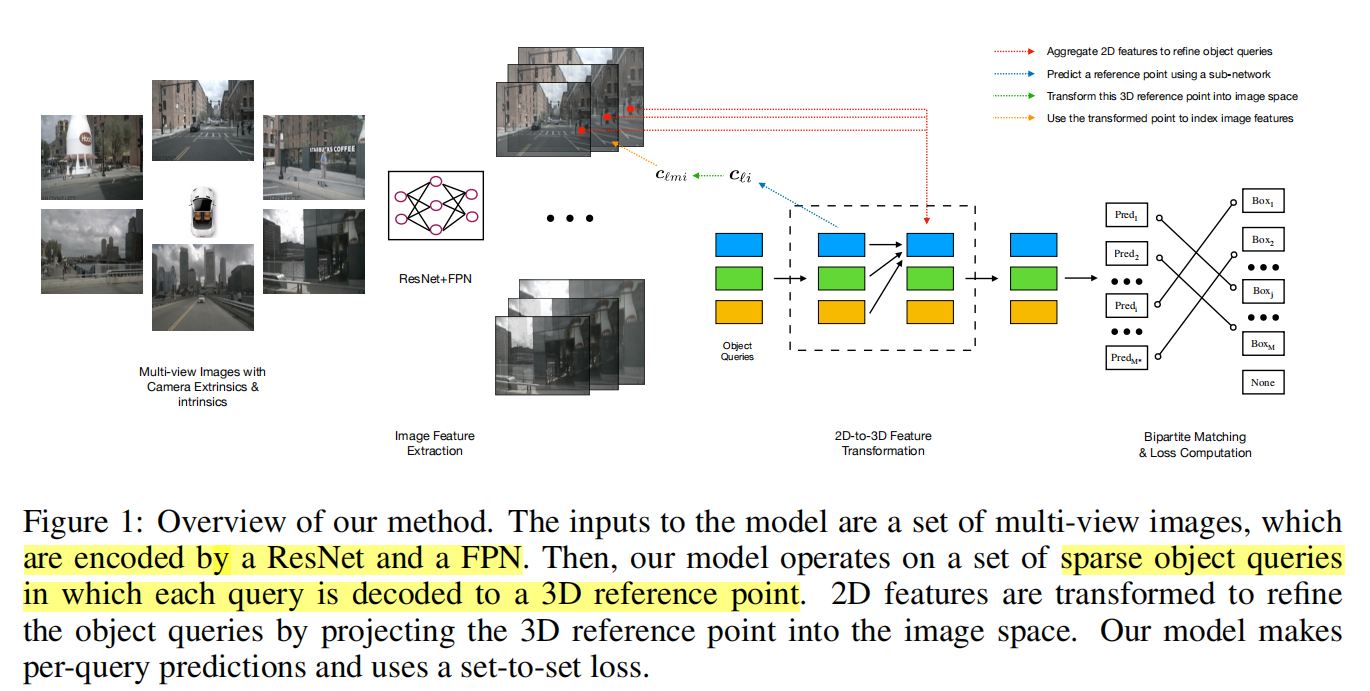
采取迭代方式,用L层layers去估计bounding boxes,以下步骤:
- predict a set of bounding box centers associated with object queries;
- project these centers into all the feature maps using the camera transformation matrices;
- sample features via bilinear interpolation and incorporate them into object queries;
- describe object interactions using multi-head attention.
先利用一个神经网络作为decoder生成reference point
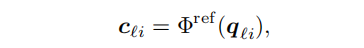
将坐标变成其次坐标并利用不同相机的转化矩阵将reference point的坐标利用透视矩阵做变换,考虑到不同level的feature maps的影响需要做归一化。

再利用双线性插值采样feature
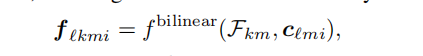
但是不是每个reference point都被被每个相机所采集,所以需要使用sigma来判断是都reference point被投影出了图像平面,最终的feature与下一层的object query由下述公式获取
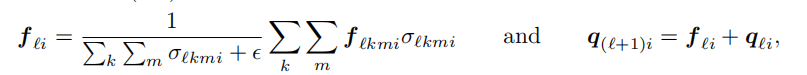
最后对每个object query,使用两个神经网络预测bounding box与类别
对迭代过程中每层都会预测,并计算loss来训练网络,但只会取最后一次的结果作为输出
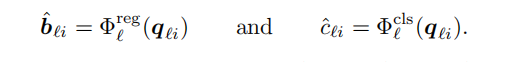
3.Loss
很显然loss源于两个因素,class prediction与bounding box parameters prediction
需要注意预测出的bounding box与ground box的数目不同,预测的往往更多,需要做padding
三、思考
1.首先肯定不能直接做3D重建再利用3D信息来做objection,因为误差是会传递的,而且这两个问题虽然逻辑上有一致性但它们的loss没有明显的正相关性,而且3D重建的error与loss难以控制。
特斯拉的做法:先直接将相机标定信息作为一个vector一起作为输入;之后又改为用一个变换矩阵对输入的每张图像做一次处理
我觉得可以学习特斯拉的做法,这篇paper看下来对于不用像机之间的联系是将inference point通过透视变换投影到原来的图像平面上,我感觉多视角的信息还是没有很好的结合在一起
2.这篇论文的流程:神经网络作为encoder提取特征–>>object queires作为decoder生成对应的inference point的3D坐标–>>根据相机矩阵映射会图像平面–>>双线性插值提取局部特征–>>利用局部特征用网络去预测box和category
转了一圈最终落脚点还是在图像信息上,3D坐标的计算也是个黑箱,哎,不是很懂。只是感觉对于3D的高纬度信息的产生和利用有点少。