论文学习之K-net
一、背景与构想
1.背景
三类分割任务:semantic、instance、panoptic segmentations,虽然有潜在的关联性,但此前的解决方案各不相同(specialized).
2.构想
作者希望能提供一个统一的架构解决这些segmentation的问题,方法是利用learnable kernels,每个kernel为一个object或stuff生成一个mask。
- 首先是一个统一的架构,用于解决联系三类segmentation问题
- 随机初始化一系列卷积核,在不同任务中学习不同参数。semantic categories–>>sementic kernels;instance identies–>>instance kernels;sementic kernels+instance kernels可以解决panpotic segmentations
- bipartite matching策略,最终建立起instance和kernel的映射关系;此外可以做到NMS-free和Box-free,有利于实时性。
二、前人的工作与问题
1.semantic segmentation
很多研究者将这个视为一个dense classification的问题,很多方法基于FCN。在FCN的基础上,许多研究者研究更好的特征表示方法,通过做dilated convolution、pyramid pooling、context representations、attention mechanisms、transformer来提升性能
2.Instance Segmentation
两种代表框架:”top-down”与”bottom-up”
top-down: 先精确探测bounding boxes,再对每个box生成一个mask.
bottom-up: 先做semantic segmentation再将同物体像素聚合成一个instance
整体而言,top-down的效果更好,但是两者都存在的问题是:Instance segmentation任务都被分成的两个步骤解决,K-net通过将kernel与预测mask建立对应关系,可以同时做segmentation和instance separation.
3.Panoptic Segmantation
如何将sementic segmentation与instance segmentation结合在一起地问题。
可以在实例分割的基础上增加一个语义分割的branch;也可以在语义分割的基础上做pixel grouping
(待补充)
4.Dynamic Kernels
很多工作对卷积核的利用都是静态的,agnostic to the inputs。泛化能力不强,之前关于dynamic kernels的研究专注于提升模型的灵活性,增加感受野等。
三、做法
1.K-Net
首先定义’meaningful group’:每张图片对应输出一个meaningful group,在不同的分割任务中有着不同的meaningful group,可以将meaningful group理解为一个样本空间。在semantic segmantation中,这个group包含所有可能的class;在instance segmentation中,这个group是一张图片可能包含的instance的集合;在panoptic segmentation中,这个group包含所有objects和stuff。
同时每张图片对应的meaningful group是一个可数有限集,不妨令group包含的最大元素数是N。K-Net将三类group统一起来,使用N(预定义参数)个kernel,每个kernel对应输出group的一个元素,要么是一个potential instance,要么是一个 semantic class。
做法:
$$
feature\ map: F\in R^{B\times C\times H\times W} \
N\ kernels: K\in R^{N\times C} \
segmentation\ prediction\ M\in R^{B\times N\times H\times W} \
M\ =\ \sigma(K\times F)
$$
输出B张图像,经过深度神经网络生成fearure maps F,再利用N个kernels与F做卷积,经过激活函数输出prediction map M。每一张image,M输出N个group元素,每个group元素是一个HXW的张量
优势:
同时做segmantation与instance detection,做法简便且迅速
但是,如何更新kernel的参数?如何定义loss function?
2.Group-Aware Kernels
解决参数更新的问题
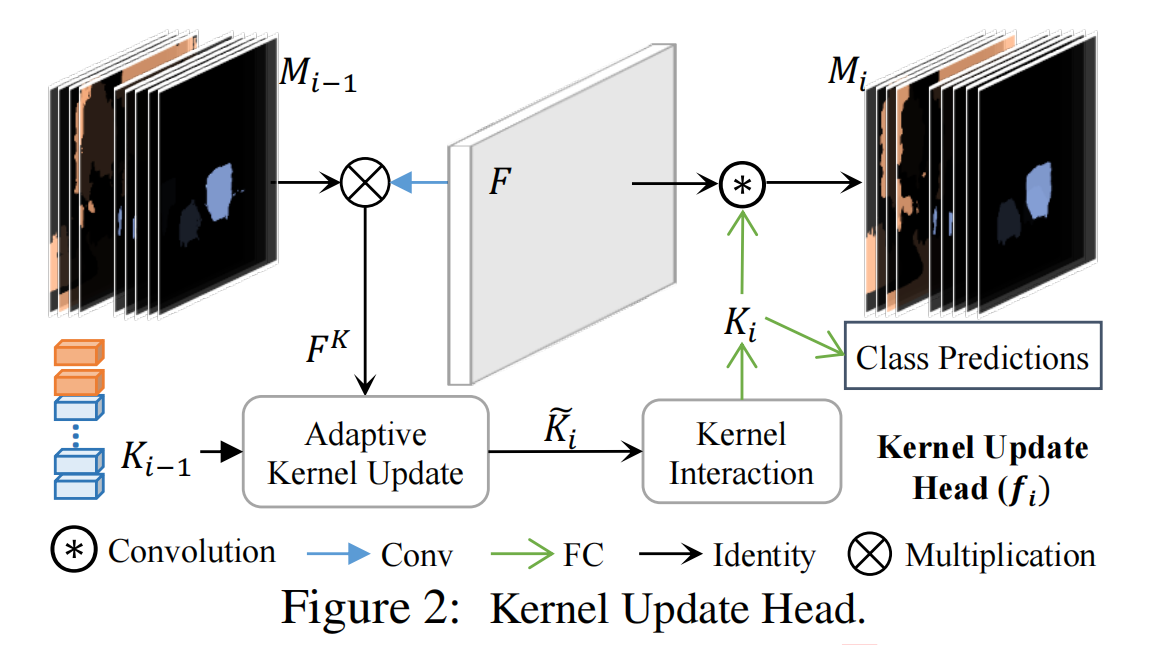
三个步骤:group feature assembling + adaptive kernel update + kernel interaction
迭代过程:
- 使用prediction map Mi-1装配得到group feature FK,FK表征每个group元素的特征与差异性
- 使用FK更新kernel Ki-1
- kernel相互交互综合建立起图像内容
- 使用得到的Ki做卷积得到prediction map Mi
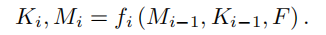
框架
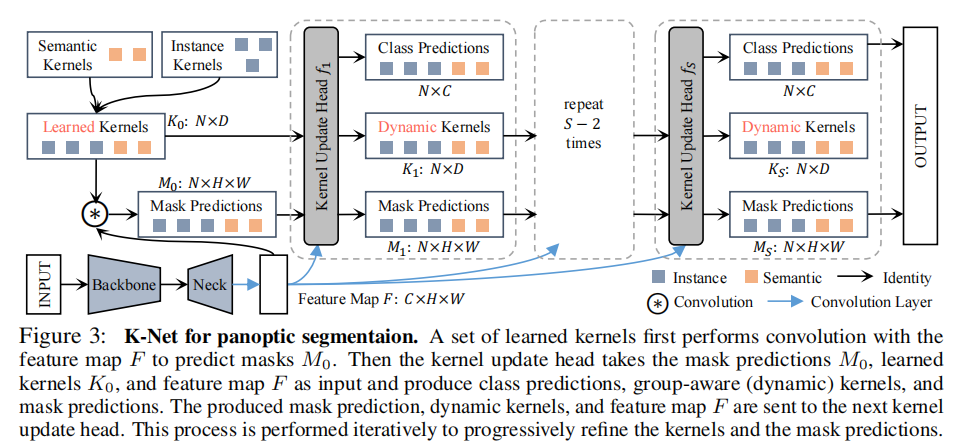
(具体class predictions与mask predictions是怎么完成的?是耦合在一起,直接通过Kernels得到吗?还是又训练了一个分类器来对Mask做prediction?不对,按照论文思路是同时产生的,直接根据group feature吗?怎么同时产生?)
2.1 Group Feature Assembling
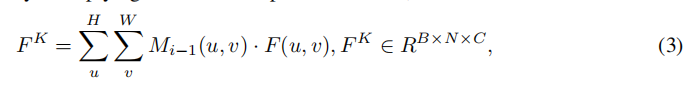
2.2 Adaptive Feature Update
prediction Map M的维度是NXHXW,每个Group元素的规模是一张图像的大小,所以可能会不可避免的产生一些噪声。为了减少噪声的影响,使用自适应的kernel更新策略
首先对FK与Ki-1做element-wise multiplication
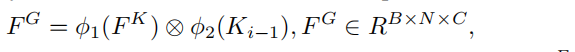
两个函数表示线性变换
随后Head学习到两个门限GK和GF,并用他们和前面的FK与Ki-1一同更新K
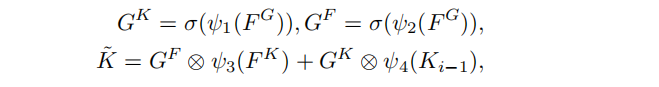
四个函数表示不同的fully connected(FC)layers followed by LayerNorm(LN),激活函数是Sigmoid
得到的K用于kernel interaction
gate functionGK和GF的角色类似于transformer中的self-attention机制,形式也非常相似。
2.3 Kernel Interaction
目的是为了使每个kernel能知道其他group的信息
使用Multi-Head Attention followed by a Feed-Forward Neural Network,输出就是新的Ki,并用来生成新的mask prediction Mi
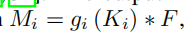
gi是FC-LN-ReLU layer followed by an FC layer.
ki同时也会用于intance segmentation和panoptic segmentation中的类别预测
3.Training Instance Kernels
1.class、instance number与kernel的匹配问题
semantic kernel:固定每个kernel对应的semantic class
instance kernel:使用bipartite matching作为map策略(不懂)
2.损失函数
$$
L_K = \lambda_{cls}\times L_{cls}+\lambda_{ce}\times L_{ce}+\lambda_{dice}\times L_{dice}
$$
Lcls由classification产生,Ldice和Lce是分割问题的CrossEntropy loss和Dice Loss。
作者使用Dice的原因是:当instances只占据图片的很小一部分的时候,交叉熵损失不足以用于处理如此不平衡的学习目标。
3.Mask-based Hungarian Assignment
用于target分配,在predicted instance masks与ground-truth instances之间建立起一一映射。
Mesh Perameterization
1.no distortion = conformal + equiareal = isometric
requires surface to be developable
- planes
- cones
- cylinders
如何定义畸变?
论文学习-attention is all you need
投资学
2月24日
1.投资的定义
当前投入资金或资源以期望在未来获得收益的行为
2.实物资产与金融资产
实物资产
- 一个社会的物质财富取决于该社会经济的生产能力,为经济创造净利润
- 如土地、建筑物、机器以及可用于生产产品和提供服务的知识
金融资产
- 对实物资产的索取权
租赁合同属于金融资产
实物资产:客户友好、大学教育、商业信誉
3.金融资产分类
固定收益型证券
金融市场与经济
造假的原因:
- 和股东交待
- 面临退市的危险
- 吸引投资者,吸引资本的流入
金融市场作用
- 信息作用
- 资金的空间转移
- 资金的时间转移,例如未来的钱现在花费(比如房贷),又比如当前的钱存到未来
- 风险分配;保险公司,购买保险也是一种风险转移;投资者可以选择满足自身特定风险偏好的证券
- 所有权和经营权的分离:获得稳定性的同时也引发了代理问题
5.市场是竞争的
需要权衡风险与收益
有效市场假说:
产的现有市场价格能够充分反映所有有关、可用信息的资本市场。通过交易来调节价格,所以市场价格的核心是交易与流动性
同时与市场管理相关
积极型管理:
- 发现误定价的证券
- 把握投资时机
消极型管理:
- 无需花费精力去发现被低估的证券
- 无需把握证券时机
- 持有高度多样化的投资
4.投资过程
两类决策:
- 资产配置决策
- 证券选择决策
Tips:
货币市场与资本市场的区别:
货币市场和资本市场的功能不同,所交易的证券期限、利率和风险也不同。资本市场是长期资金的融通市场,货币市场是短期资金融通市场。货币市场交易的证券期限不超过1年。资本市场是指期限在1年以上的金融资产交易市场。货币市场的主要功能是保持金融资产的流动性,以便随时转换为现金。资本市场的主要功能是进行长期资金的融通。货币市场工具包括短期国债(在英美称为国库券)、可转让存单、商业票据、银行承兑汇票等。资本市场的工具包括股票、公司债券、长期政府债券和银行长期贷款等。资本市场包括银行中长期存贷市场和有价证券市场。与货币市场相比,资本市场交易的证券期限长(超过1年),利率或必要报酬率较高,其风险也较大,具有长期较稳定收入,类似于资本投入。
3月10日
1.核准证与注册制
论文学习-FCOS
一、前人的工作与问题
目标检测需要一组预定义好的anchor box,存在一些缺点
- 对物体大小以及长宽比的变化比较敏感(确实,对于同一个物体,根据相机距离远近的不同,成像大小也不同,需要不同的框去包围;同时对于形态的变化也需要进行相应调整;anchor box的大小应该是能自适应调整的;什么特征会与anchor box大小相关?)
- anchor-based detector需要密集地将anchor box放置在图像上,而绝大多数都是负样本,一方面计算量太大,另一方面正负样本的比例失衡,不利于模型的训练
希望设计FCN的框架去生成anchor-free的detector
二、做法
per-pixel prediction + multi-level prediction+’center-ness’branch
1.Fully Concolutional One-Stage Object Detecor
训练数据:输入image的anchor box由五元向量构成:四个anchor坐标+一个class坐标。将每个位置的pixel的信息作为training samples。对于处于(x,y)的像素,如果它落于任何ground-truth anchor box中且类别正是anchor box所框中物体的类别,则认为它是正样本;否则是负样本,类别为0(用于描述背景的类别);而如果落在多个box中则认为是一个ambiguous sample.
regression target:对于每个位置的像素,预测四元距离向量,即与bounding box四条边的距离
network outputs:同regression target再,加上一个class vector。class vector是一个C维向量,利用的是C个二元分类器而不是一个多级分类器。
优势:在训练过程中可以充分利用foreground samples.
网络架构与Loss function:

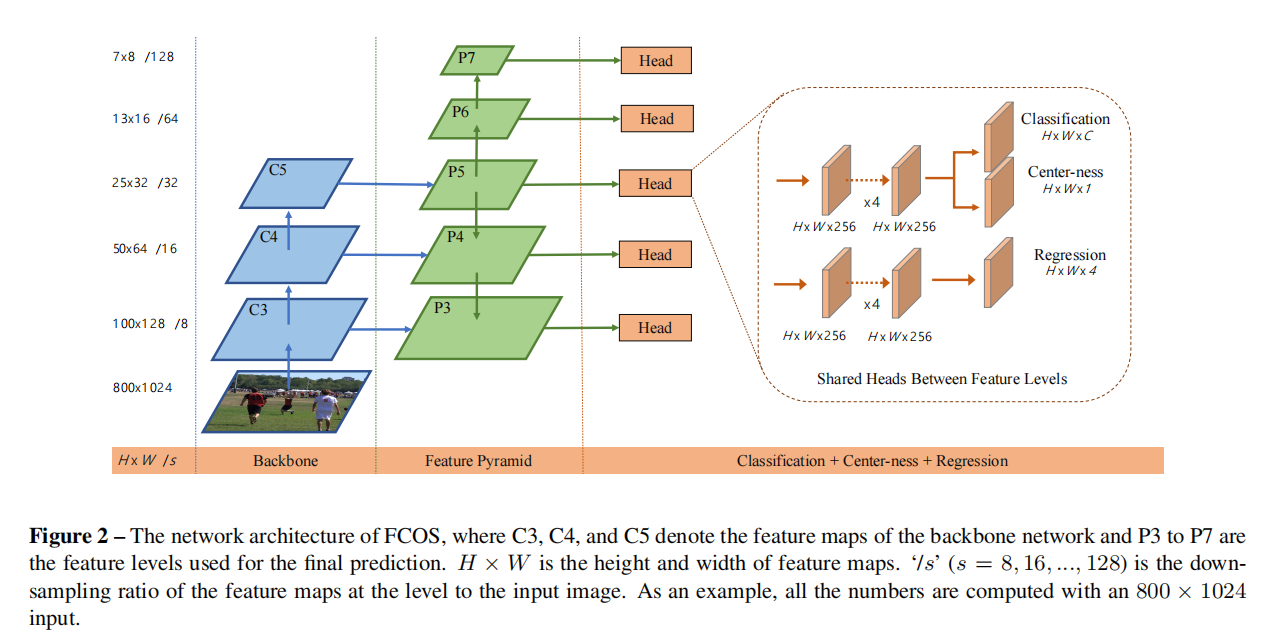
2.Multi-level Prediction with FPN
两个可能存在的问题:
- 用CNN处理具有大步长的feature map可能带来较低的BPR
- ground-truth box的重叠可能会模棱两可,该位置的像素对应哪个box呢?
做法:首先获取不同大小的feature maps{P3,P4,P5,P6,P7},在这些feature maps上做detect得到很多regression targets,对这些detect targets限制大小。最终如果一个位置的像素仍与多个box匹配,则选择面积最小的box作为结果输出。
细节:heads模块在不同feature levels中共享,优点是detector更高效且提升性能;但是由于不同feature levels得到的box的大小具有不同的范围,所以不太合理,解决方法是使用自适应的指数函数exp(six)来调整feature level Pi.
3.Center-ness for FCOS
**问题:**大量低质量的bounding box被远离物体的中心的点产生
做法:增加了一个single branch来预测一个点的”center-ness”,”center-ness”描述了从该点到该点属于的物体中心的归一化距离。center-ness 在0到1之间且用BCE训练,该loss在loss function中体现。在测试过程中,class由初始预测class与center-ness相乘得到,从而可能远离物体中心的属于物体的点在NMS步骤中被滤除。
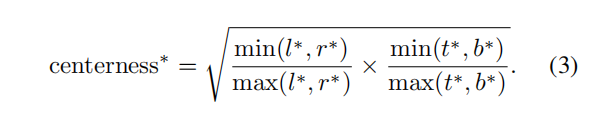
三、思考
1.anchor-box free的想法很厉害,将image-level的问题用pixel-level解决,对每个位置上的像素进行预测bounding box与class;后续的设计都从而展开;多级预测的思想也很厉害,在降采样的图像金字塔上分别做预测,能解决ambiguous sample的问题,也能增加预测结果的鲁棒性。
2.我的一些想法
关于bounding box:
是否需要绘制bounding box?bounding box依赖于该物体像素的分布,如果能准确预测每点像素的值,是否Bounding box也可以从这些像素的位置中推导得到(取到上下、左右边界即可),也即图像语义分割+类别标注+bounding box绘制能否达到同样效果?这样也能直接解决multi bounding box的问题。但是感觉对单点做分类好难。
能不能再加一个post-process:根据一个限制条件:同一物体的点的regression targets在邻域内应当是连续的,不能出现大的跳变来提高bounding box的准确性。或者在loss function中体现?
关于点:
单独的点是没有任何意义的,只有将点放在上下文中它才能构成物体或者背景,但在从实物到图像的采样过程中,点的像素值具有噪声也受光照等因素影响。CNN的卷积操作、池化操作都能起扩大感受野的作用,将孤立的点与邻域的点联系起来并提取特征,从关联性的角度看,self-attention能否起到类似的作用?不需要对整张图片做self-attention,能不能用local self-attention代替卷积?或者用self-attention与CNN相结合?
以及局部特征的提取?卷积运算简单且高效,但是固定窗口是否略显僵硬?虽然可以用不同大小的卷积进行操作。而且特征的体现还是以像素值进行表征,是否过于简单?
数学建模
Self-attention
一、Vector Set as Input
与以前遇到的问题不同,输入的是一个向量的集合。向量的数目不确定。
典型应用:NLP中语句作为输入,每个单词是一个vector,可以用one-hot编码编成向量,也可以用word-embedding包含语义信息;语音输入,以frame为单位,一定步长移动;Social-network,可以将每个节点作为一个vector;高分子结构,同样可以视为一种graph。
二、The output
1.each vector has a label
例子:
- 词性标注 I saw a saw. –>> N V DET N
- social networrk每个节点的特性
2.the whole sequence has a label
例子:
- sentiment analysis
- 预测高分子的性质
3.Model decides the number of labels tself
例子:
- 翻译
- 语音辨识
三、Type one
sequence label问题
1.self-attention作为解决方法
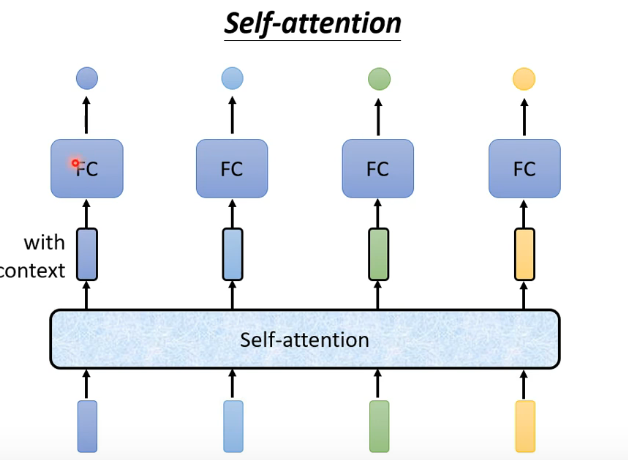
不是考虑一个frame或windows,而是考虑整个sequence作为输入
同时self-attention可以多次使用且可以与fully-conntected network交替使用
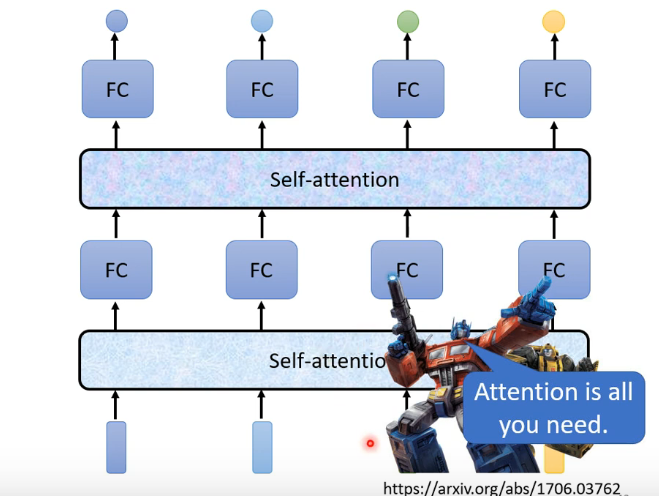
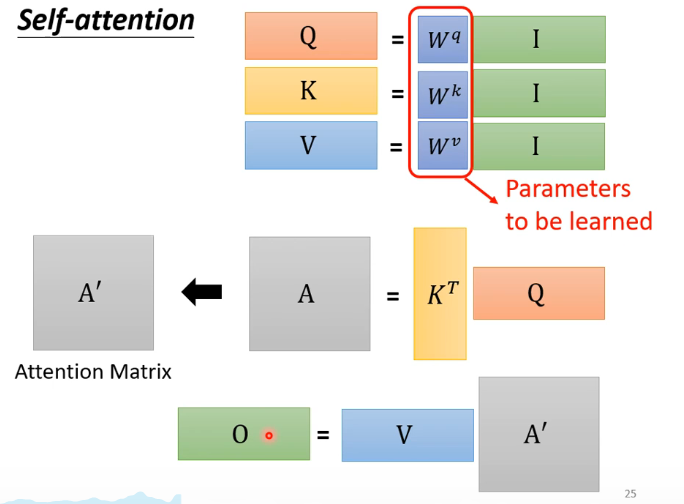
2.self-attention做法
计算一对vector之间的关联程度
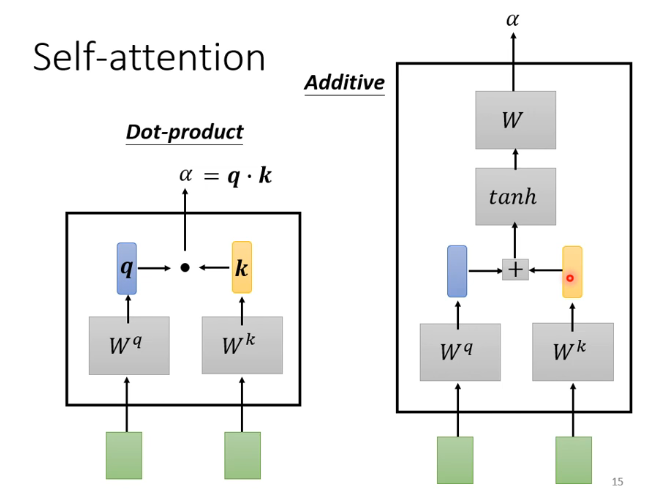
计算sequence中vector的关联程度
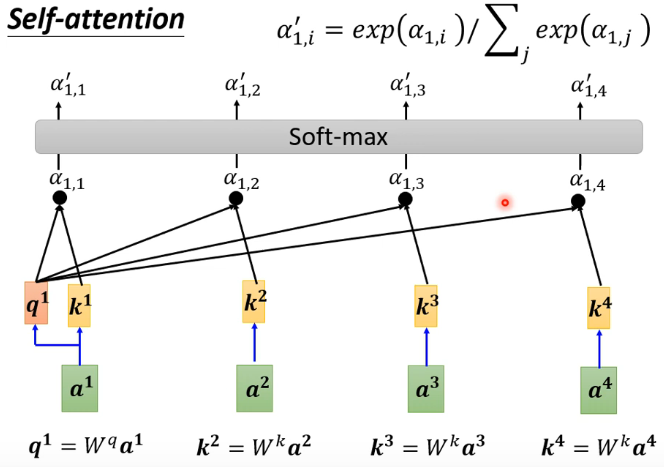
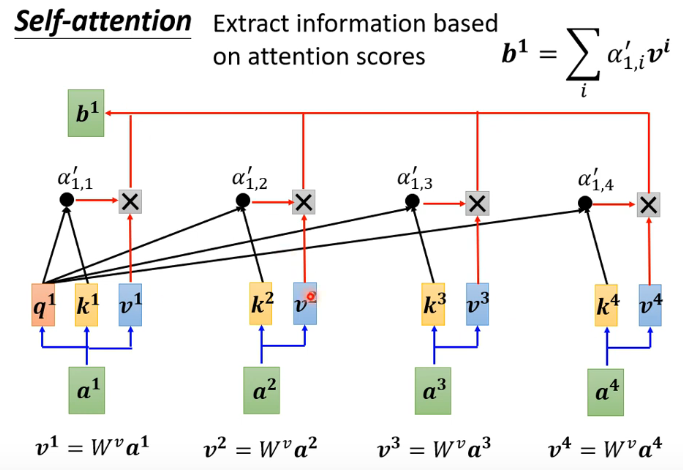
最终输出一个vector
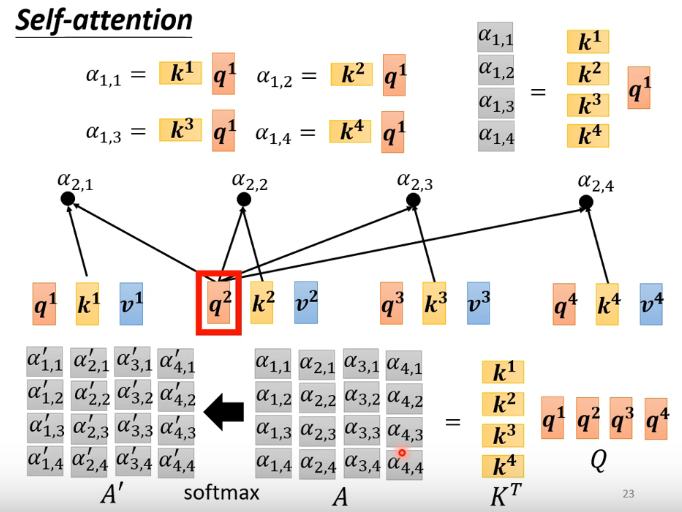
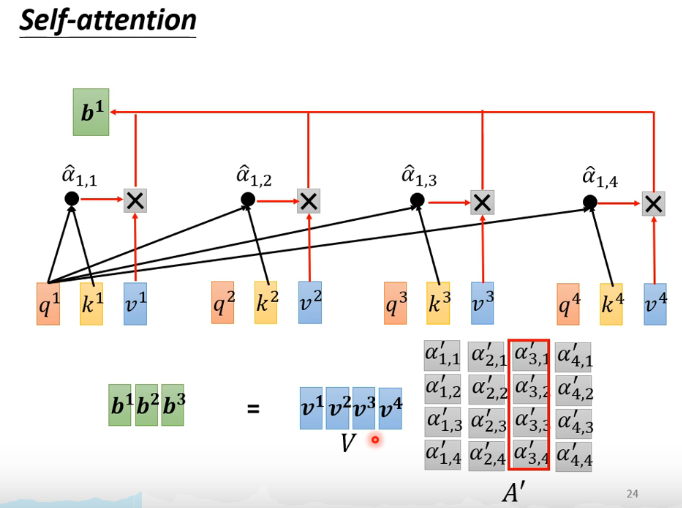
简化运算形式:
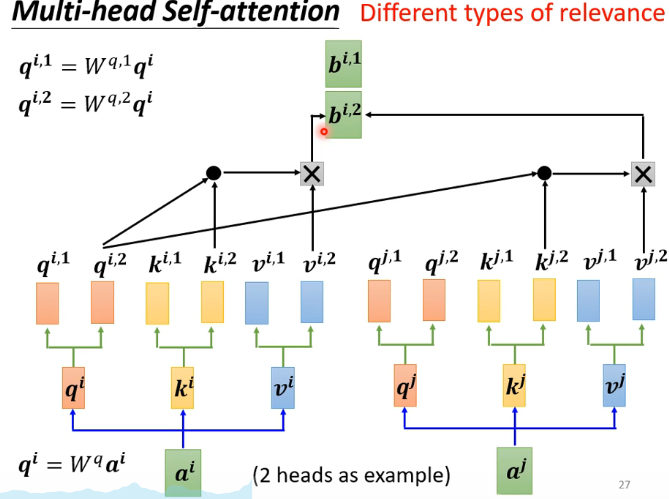
3.multi-head attention
发掘不同的self-attention
4.Positional Encoding
上述计算中并没有考虑位置信息,计算过程对称。
但如果认为位置信息比较重要则可以加进去,做法可以对每一个位置生成一个unique vector,与原来的输入相加即可。
小样本学习论文复现之DMF
1月22日
1.看了工程代码框架,可以从以下几个模块去实现:
- 命令行参数获取与解析
- 数据集处理Datasets
- 数据加载器DataLoader
- 网络架构,网络按照论文分为Resnet提取特征、连接Support Image和Query Image做动态采样、用Dynamic Meta-filter提取与空间、通道相关的特征、用Neural ODE做特征匹配、定义损失函数训练Meta-Classifier与global Classifier
自己复现的话很多参数都可以固定下来
2.学习了部分参数解析和DataLoader的语法
3.构思工程
如上有四个模块,功能集成在top.py中完成;需要为参数获取定义一个类,需要为Datasets与DataLoader定义两个类,需要搭建网络结构且由于小样本的特殊性,test与训练用的循环不能共用
4.开写
1月29日更新
前几天学习了一下pytorch语法,也摸了几天鱼,半写半抄算是把dataLoader弄出来了。
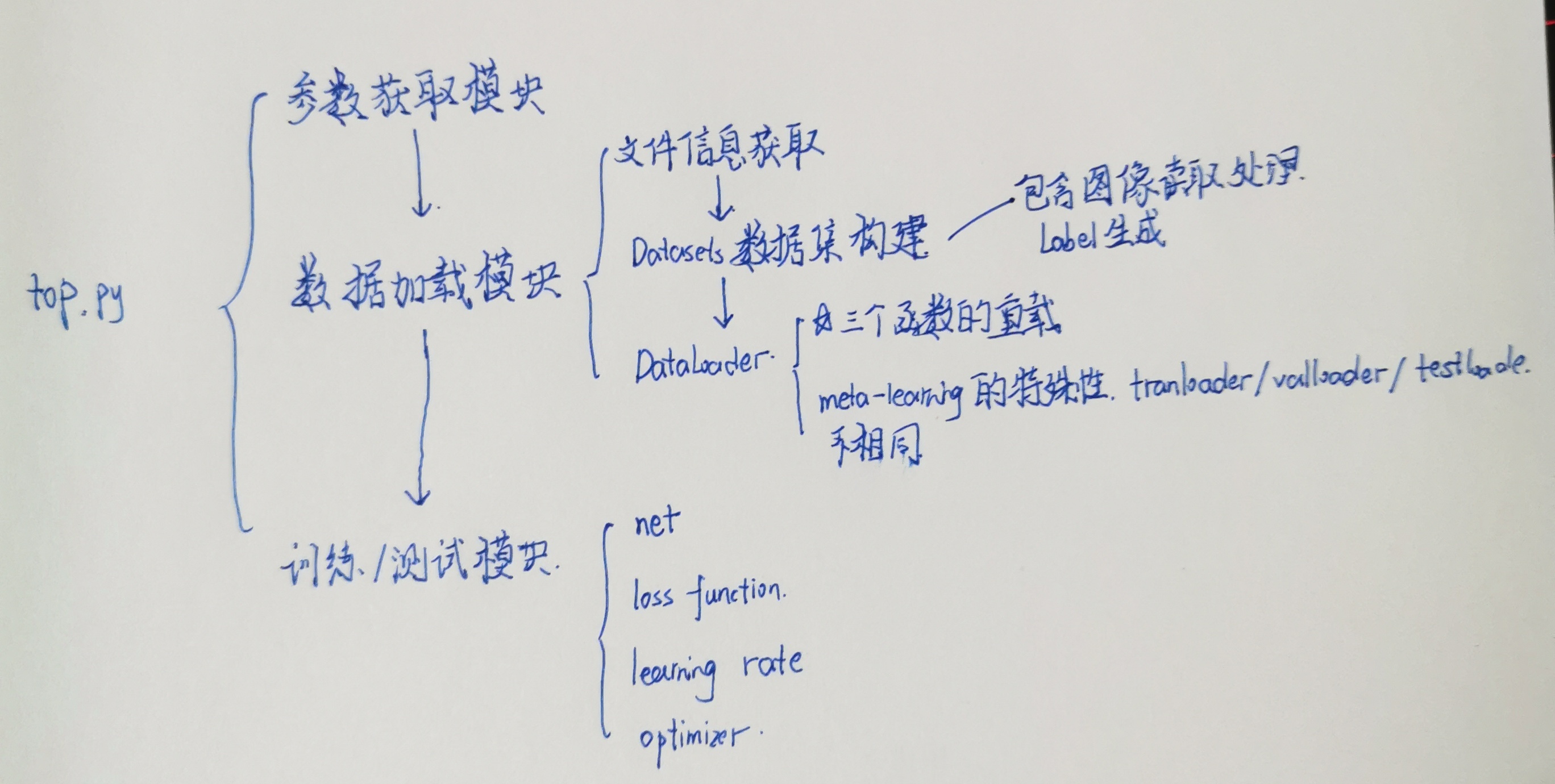
现在是完成了参数获取与数据加载。
再看了一遍论文,准备对照official code再搞搞剩余的训练与
论文学习-DMF
一、关于Few-shot Learning
Few-shot Learning与Meta-learning相似,可以视为其的一种应用,但又有区别。在图像分类领域:Few-shot Learning的目的是根据已知给定的extremly limited examples,学习到知识并用来识别新的类别。
最naive的想法是用深度卷积神经网络学习到support set中类别的一些特征,在query set做预测时直接比较特征间的相似性,但是直接使用卷积学到的特征受限很于数据,对于没有见过的类别很难泛化其分类能力。需要进一步增加模型特征提取与匹配的能力。
二、Learning Dynamic Alignment via Meta-filter for Few-shot Learning的思想
1.前人的工作
参考CAN和FEAT这两篇论文。它们的思想是aggregates support knowledge to formalize an alignment function for query samples以此达到特征匹配的目的(没看过这两篇,咱也不懂)。
作者认为存在一些缺陷:
Roughness,作者认为图像特征的空间位置的差异性(空间分辨率spaial resolution)比通道间的差异性大得多而很少有工作在提取特征是关注channel 相关特征。
如下图,特征应该是黄色区域,channel1提现得很好而channel2较差。CAN做特征匹配时会赋予两个通道相同的权重,而DMF不会
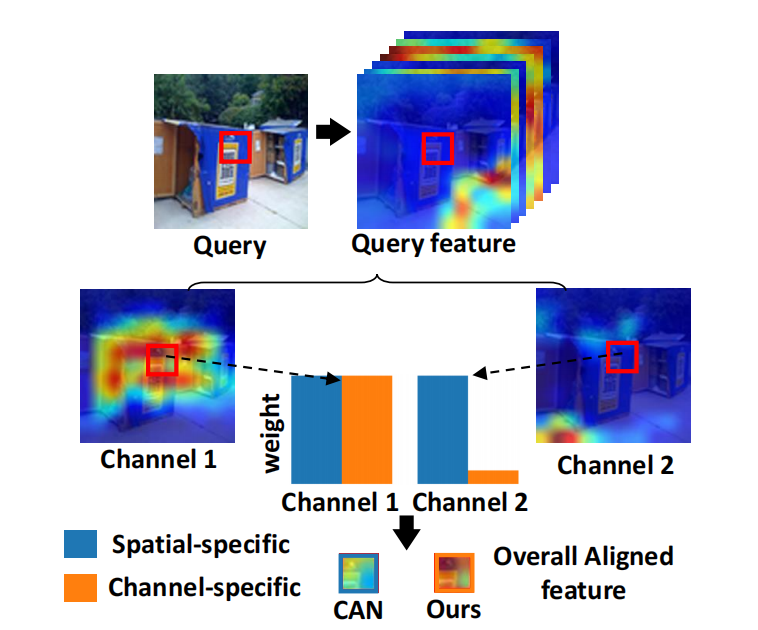
Redundant matching. 冗余主要出现在两个地方,一个是待识别的物体可能在一张图像中多次出现;其次是当 aligning each query position时,会利用所有的support feature,效率较低(不是很懂,大受震撼)。
Inflexible alignment. The alignment strategy in these works only runs one time for all tasks. Thus, for those diffificult ones, the alignment may be insuffificient to appropriately embed the support knowledge into query feature.
2.作者的方法
- Dynamic meta-filter. 用于高效特征匹配
- Dynamic sample and group strategy.提升Dynamic meta-filter的灵活性与效率。
- Neural ODE.
预测一个和空间位置、通道相关的Dynamic meta-filter,将filters应用于feature positions而不是整个support feature。Features positions不是采取的固定的而是学习得到动态采样策略。同时为了使匹配能适用于更复杂的任务而固定超参数很难控制匹配的过程、程度,所以采用ODE的方法执行residual alignment的过程并在迭代过程中自适应地调整步长以获得最终解。
在获取到aligned query feature后,将support knowledge以不可学习方式聚合在一起,利用mata-slassifier做最终的预测。
3.相关工作
1.Few-shot recognition.
目前两种主流解决策略: 一种是optimization-based methods.首先根据base class data训练一个网络,再在遇到未见过的类别、数据时微调网络或者改变整个网络架构。第二种是metric-based method,应用现成的或者学习到的图像特征做FSL。
2.Dynamic Sampling
以前的采样方法:固定大小采样,动态区域采样但是滤波器大小固定。
作者:先用动态采样策略获取feature position的邻域再再这个区域上预测得到与位置和通道相关的滤波器。
3.Input dependent weights
也是learnable module的一种体现,weights不是直接优化得到而是与输入数据相关。
4.Neural Ordinary Difference Equation
Neural ODE将神经网络的前递视作ODE的一种离散形式(???为什么是离散的?因为网络架构是固定的吗?)。在此情况下,可以加入一个时间变量控制输出以使得修改neural networks为neural ODE。
三、DMF架构与操作
1.DMF架构
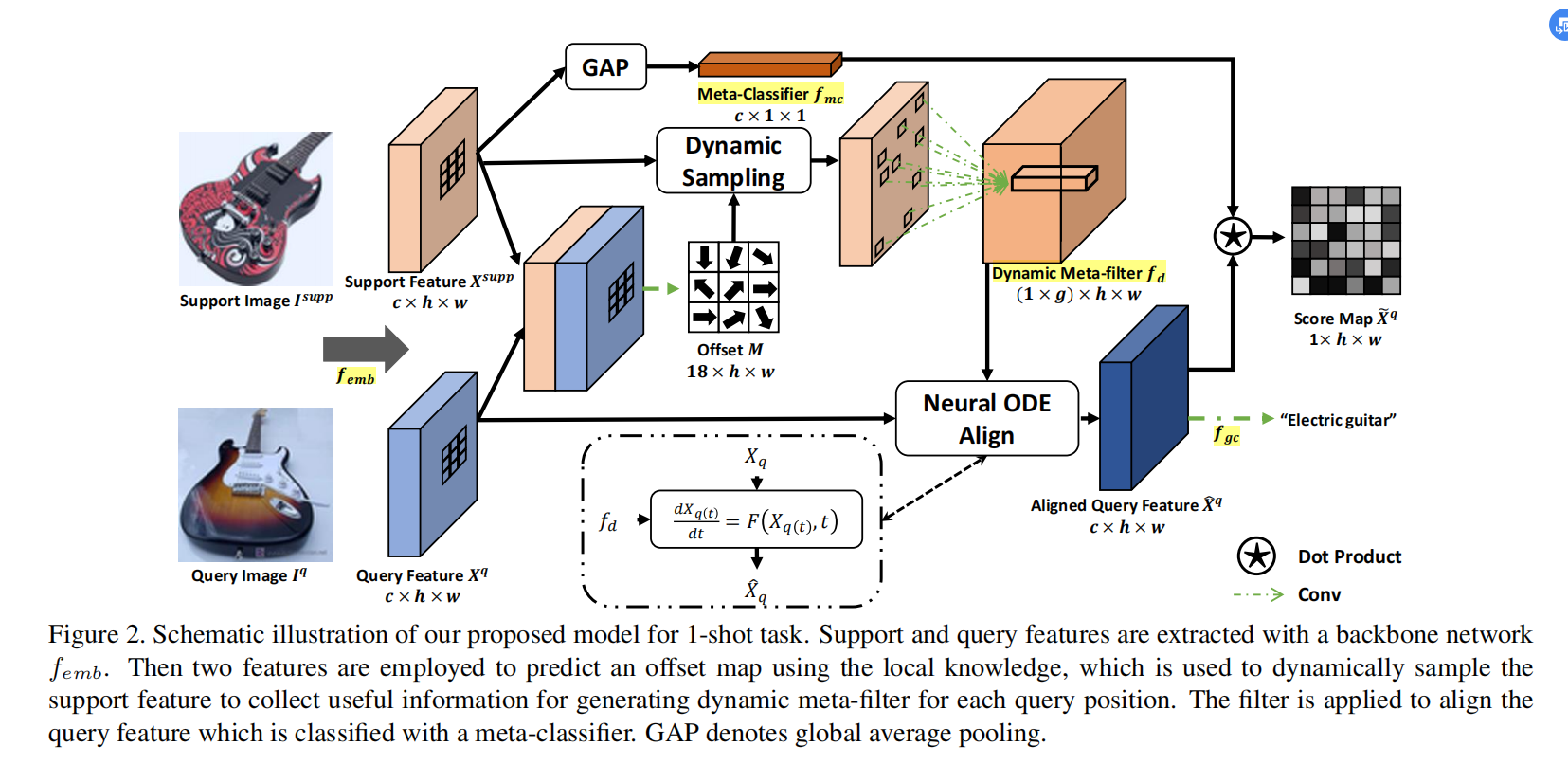
包含四个子模块:特征提取器femb,动态匹配模块fd, meta-classifier fmc, global-classifier fgc. 在一次Episode中,给定每对support image和query image,首先利用特征提取器提取得到大小为[c, h, w]的feature maps,对应channel,height和width;再动态采样获取特征;用fd进行特征的动态匹配;最后用fmc根据query feature与support feature之间的相似性输出confidence score.
2.DMF(Dynamic Meta-filter for Adaptive Alignment)
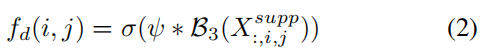
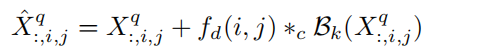
对support feature先做一次卷积,卷积核大小为3,输出通道为c x K x K,可以视为图像每个位置的像素对应一个c x K x K大小的张量,再将其视为该位置一个输出通道为c,核大小为K的卷积核。对query feature的每个位置使用对应的卷积核进行group为3的分组卷积,与原本的query feature相加得到aligned query feature.
值得注意:channel wise正是通过分组卷积实现的。每个K x K的卷积核对应于原query maps中的一张query feature。
3.Dynamic Sampling
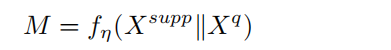
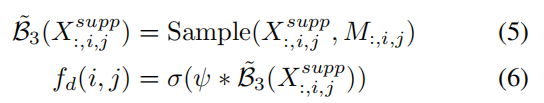
先将support feature与query feature拼接在一起,用核大小为5,通道为9的卷积核进行卷积,生成一张9 x h x w的feature mapM。M的每个位置的9个数值包含生成在位置(i,j)的卷积核的信息。
4.Adaptive Alignment
重复匹配过程
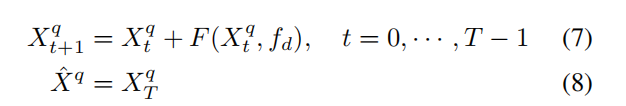
F是前面的动态卷积的过程。问题是超参数T的调整,对于FSL,面对不同的任务,超参数T应该不同,所以作者使用了Neural ODE的方法。
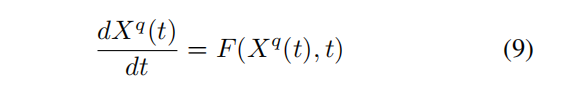
5.Meta classifier
获取Dynamically aligned query feature后,不需要任何可学习参数生成一个meta-classifier。方法:使用glaobal averge pooling将support feature聚集到一个c x 1 x 1的feature上,将这个c x 1 x 1的张量作为一个卷积滤波器,也即架构中的fmc,并运用在aligned上可以得到一个1 x h x w的张量。如果query set中某张图属于category c,则它们对应位置应该有很高数值。
四、实现细节
1.损失函数

2.网络架构
使用ResNet12去除最后的池化层用于特征提取,feature map