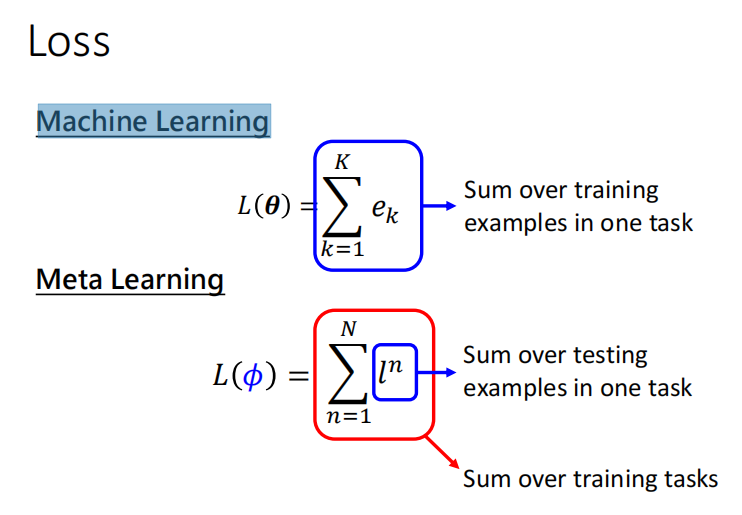
Meta Learning则是指learning about learning。目的是使机器具有学习的能力,通过在任务A、B、C上的学习,能迅速掌握解决任务D的方法。具体的,根据李宏毅老师的课程:我们相当于要学习到一种Learning algorithm,以分类任务为例,我们可以输入二分类任务,如分类苹果和香蕉、太阳和月亮的任务,通过训练掌握Learning algorithm后可以很快解决猫猫和狗狗的分类问题。也有三个步骤:先决定what is learnable?典型的learnable component有网络框架、初始化参数、学习率等;随后定义损失函数;第三步依旧是优化器优化learnable component。在训练过程中每轮迭代解决一个训练任务,任务具有训练数据与测试数据,在训练数据上训练,损失函数定义在训练任务的测试数据上以评估该任务上训练出模型的好坏。最终meta-learning会在测试任务上进行测试,根据表现判断learnable component是否被学到了。
二、一些术语
每轮训练的输入是一个training tasks, training tasks的数据分为Support set和Query set,分别用于该任务的训练和测试。一次训练成为一个Episode。
= Ambient Term + Disfussion Term + Specular Term
但是Blin-Phong模型是一个很简化的模型
关于Shading Frequencies
Flat shading.三角形取三个点,确定一个平面,平面内色素值相同
Gouraud shading:对顶点上取点做shading,内部差值
Phong shading:对每个像素做shading
问题:
逐顶点的法线:用该顶点相邻面法向的平均,是否需要根据相邻面的大小进行加权平均?
已经知道顶点法线,如何得到内部点平滑的法线方向?
给顶点差值得到(利用重心公式)
Graphics(Real-time Rendering) Pipeline(图形管线)
1.含义:一些列操作,从三维空间中的点到图像
Input: vertices in 3D space –>> Vertices positioned in screen space –>> Triangles positioned in screen space –>> Fragments –>> Shaded fragments –>> Output: image
classDataLoader(object): """ Data loader. Combines a dataset and a sampler, and provides single- or multi-process iterators over the dataset. Arguments: dataset (Dataset): dataset from which to load the data. batch_size (int, optional): how many samples per batch to load (default: 1). shuffle (bool, optional): set to ``True`` to have the data reshuffled at every epoch (default: False). sampler (Sampler, optional): defines the strategy to draw samples from the dataset. If specified, ``shuffle`` must be False. batch_sampler (Sampler, optional): like sampler, but returns a batch of indices at a time. Mutually exclusive with batch_size, shuffle, sampler, and drop_last. num_workers (int, optional): how many subprocesses to use for data loading. 0 means that the data will be loaded in the main process. (default: 0) collate_fn (callable, optional): merges a list of samples to form a mini-batch. pin_memory (bool, optional): If ``True``, the data loader will copy tensors into CUDA pinned memory before returning them. drop_last (bool, optional): set to ``True`` to drop the last incomplete batch, if the dataset size is not divisible by the batch size. If ``False`` and the size of dataset is not divisible by the batch size, then the last batch will be smaller. (default: False) timeout (numeric, optional): if positive, the timeout value for collecting a batch from workers. Should always be non-negative. (default: 0) worker_init_fn (callable, optional): If not None, this will be called on each worker subprocess with the worker id as input, after seeding and before data loading. (default: None) """