论文阅读-FCOS3D
论文阅读-PGD
CG课程论文--High-quality Motion Deblurring from a Single Image
一、问题背景
1.模糊图片的产生
在latent image的基础上,由于相机的抖动相当于一个blur kernel作用在图像上(或point spread function).此外图像的拍摄过程也会存在噪声。同时在估计blur kernel的时候也会产生误差,这些误差在以前的解决方案中被归到image noise中了,是不对的
2.blind or non-blind问题
区别在于kernel是已知的还是未知的
3.作者方法的核心:
- 概率模型的构建,合理分析artifact的产生原因,以及各个部分的noise。本文认为噪声分布是spatially random distribution
- smoothness constraint
- optimization algorithm
二、Analysis
1.理想情况下产生实际的blurred image
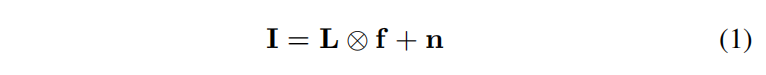
I是latent image, f是psf或blur kernel。二者做卷积加上图像噪声生成一幅blurred image
恢复图像的难点在于ringing artifacts,以前的研究认为这源于Gibbs phenomeno,即傅里叶级数在自然图像不连续阶跃处的误差造成,但作者的研究发现ringing artifacts更可能源于对图像噪声与psf估计中产生的误差的混淆
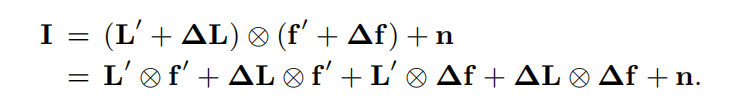
如果不能对噪声n合理建模,会容易把在优化过程中产生的对Iatent image和blur kernel的误差归到noise中。而以前对noise往往认为其和其一阶导服从均值为0的高斯分布,这是一个很弱的约束。
三、Model
1.概率模型
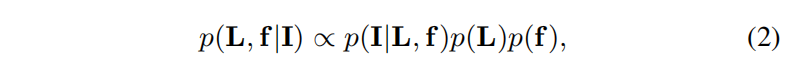
右边分别是似然概率**p(I|L,f)**还有概率先验
2.似然概率
在已知latent image和psf的条件下估计拍摄到的图片,根据第一个表达式,也相当于在估计噪声。噪声在x于y轴上的偏导用差分替代。高阶微分同理
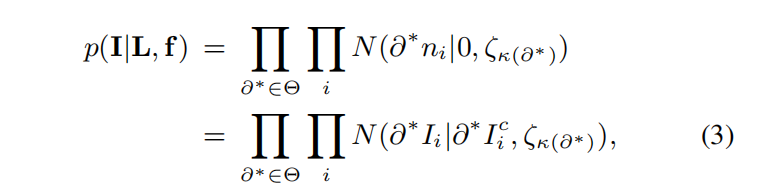
认为噪声、噪声的一阶导数、二阶导数符合高斯分布
3.kernel先验
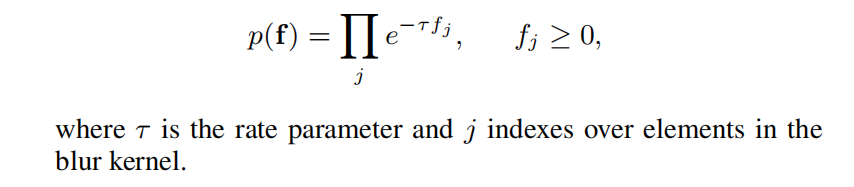
4.image先验
由两部分组成,Global prior和Local prior
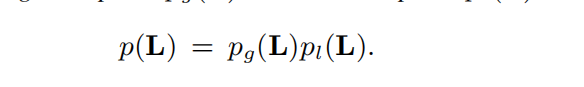
4.1 Global prior
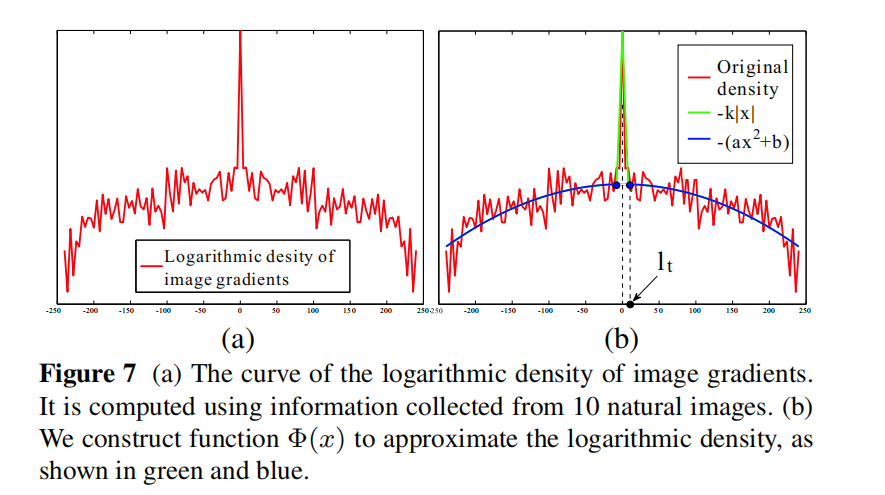
研究图像的自然梯度并进行拟合
拟合函数:
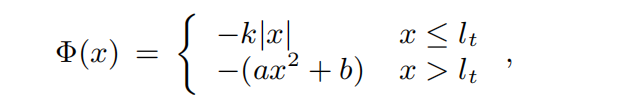
4.2 Local prior
为了消除ringing artifacts而引入,基本思想:运动模糊可以被视为平滑滤波过程(smooth filtering process),在模糊图像局部,像素应该具有constant color
对于blurred image中的每个像素,生成一个和blur kernel相同大小的local window,计算window内颜色的标准差,如果小于某个阈值则认为该像素在区域内
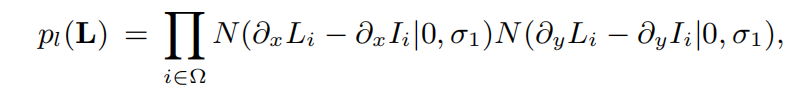
sigma1是标准差
四、Optimization
1.定义能量函数为似然概率的负对数
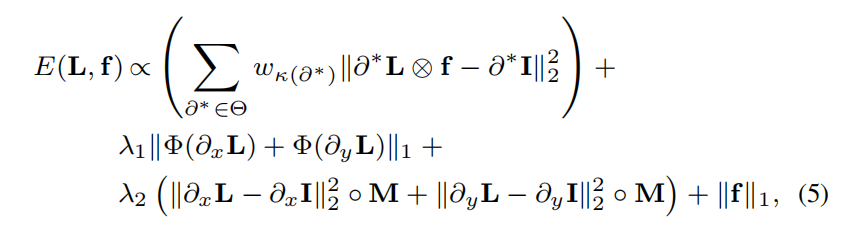
上图是优化目标,目标参数是L和f,还涉及到L的多阶导数,很明显并不能直接优化。此外还有参数lambda等的设定
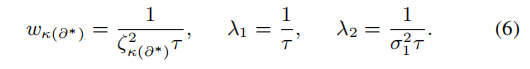
lambda的设定之后再说明
优化顺序是L、f
1.1优化L
规定f则优化函数变为:
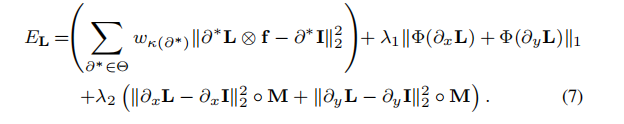
但是L同时涉及卷积、一阶导与高阶导,想将卷积操作与外面两项的优化分离开,所以先利用参数 Psi来近似L的一阶导
优化目标转为:
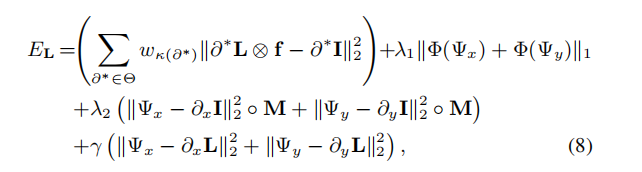
最后一项可以视为正则项,正则项系数不断增大,Psi与L的一阶导的偏离越大,惩罚越大
固定第一项,利用后面的项更新Psi
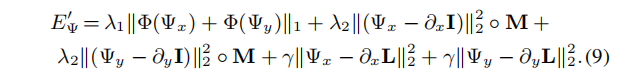
从x和y两个方向进行优化
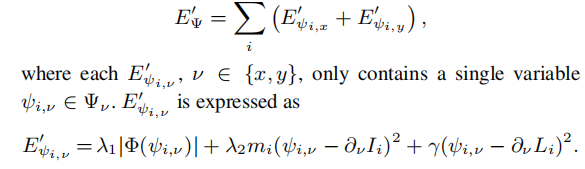
最终能得到使全局最优的Psi
更新L,在Psi固定的条件下
Dter3D论文重新阅读
关于transformer的疑问
其他研究者对自动驾驶的研究
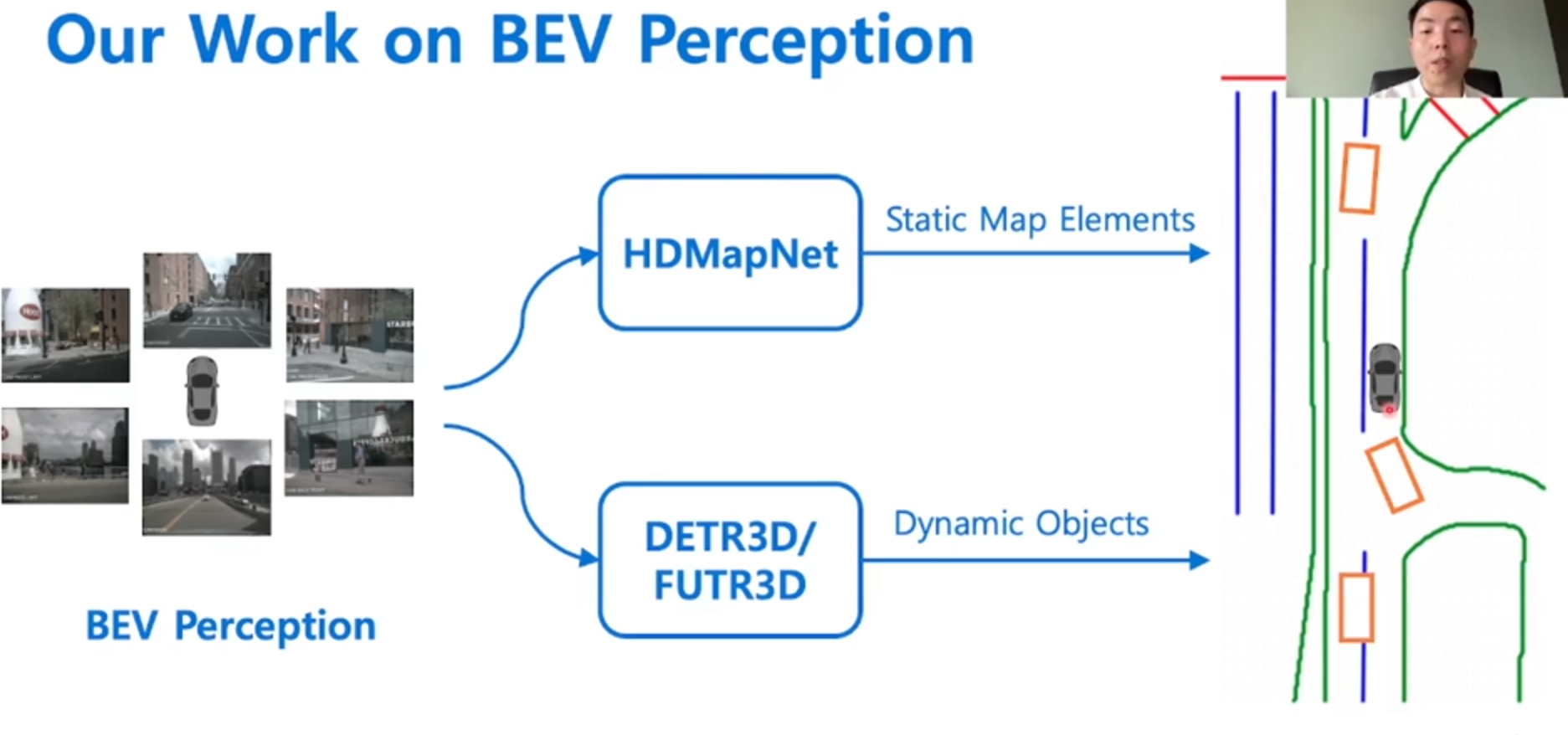
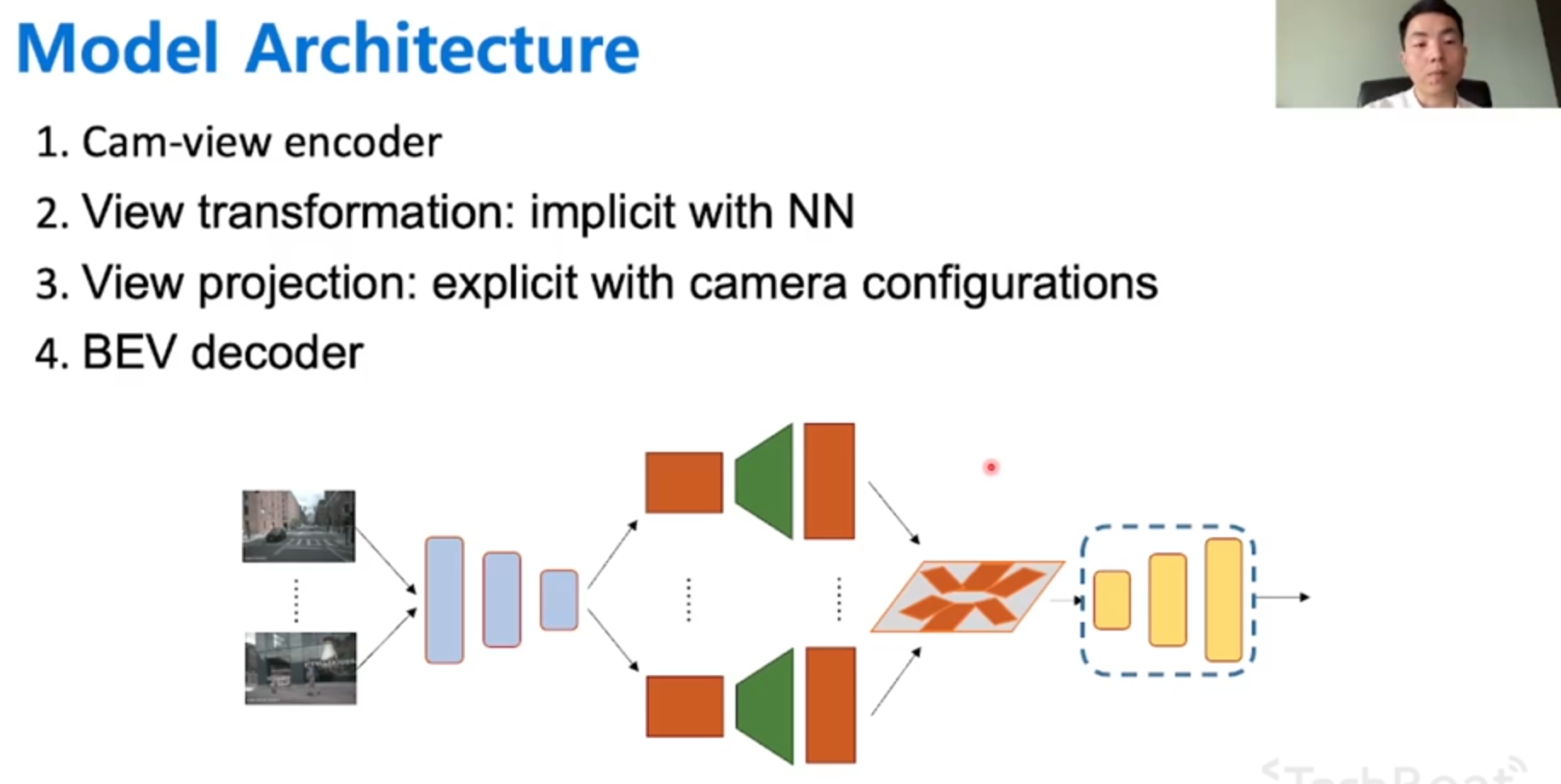
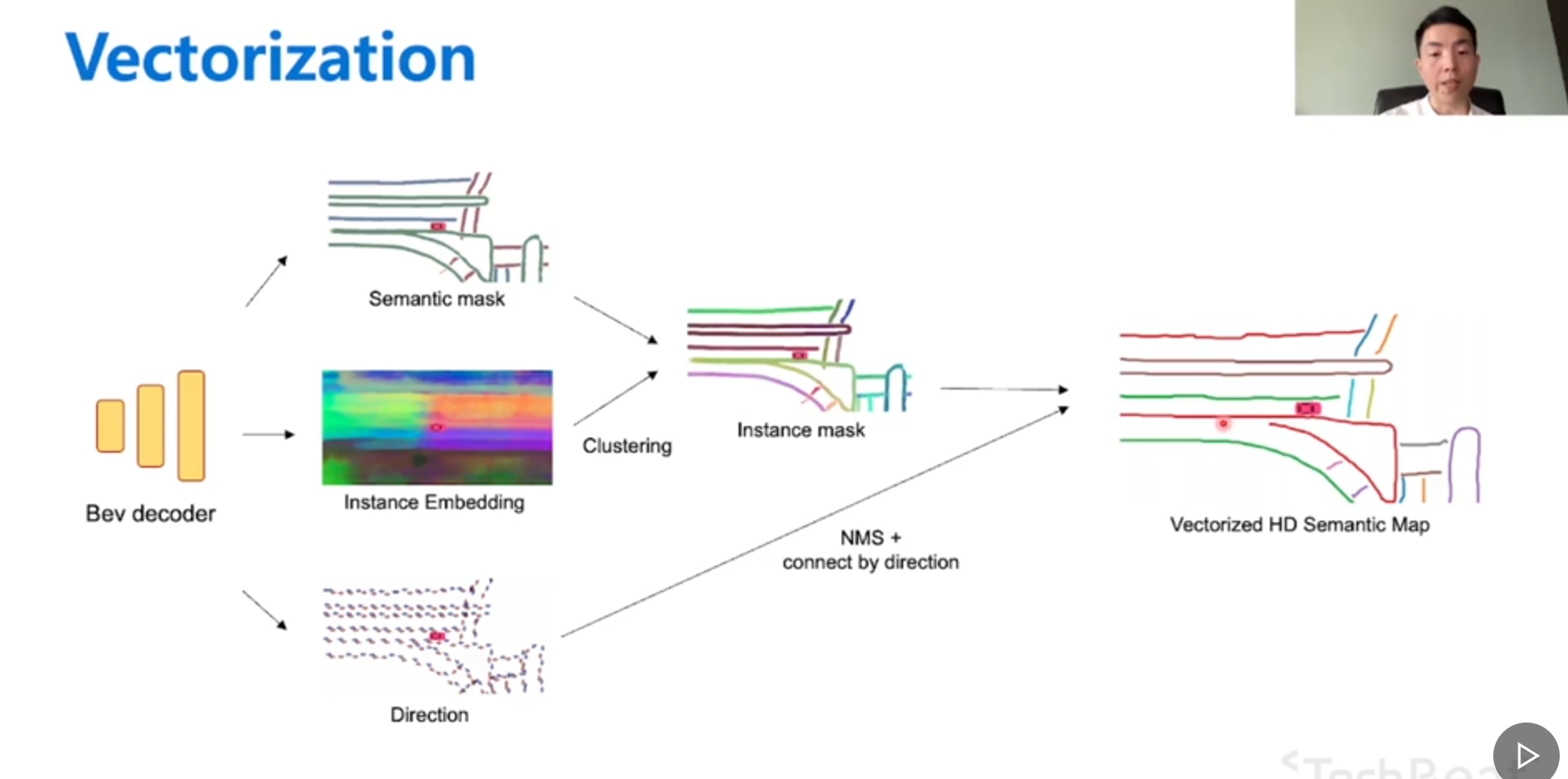
编译原理
Chapter 2 词法分析
0.概述
词法分析(lecical analysis)的作用:将原程序读作字符文件并将其分为若干个记号,记号是一个字符序列。三类字符:关键字(key word),标识符(identifier),
步骤:
- 给出扫描程序的概貌
- 正则表达式与自动机
- TINY描述程序的完整实现
- 扫描器生成器的过程和方法,并用Lex再次实现TINY的扫描程序
1.扫描处理
从源代码中读取字符并形成由编译器的以后部分(通常是分析程序)处理的逻辑单元。
记号:名称、属性。撒尿程序必须计算每个计算的属性并将所有属性收集到一个单独构造的数据类型中,成为token record.
2.正则表达式
在正则表达式中有3种基本运算:① 从各选择对象中选择,用元字符|(竖线)表示。②连结,由并置表示(不用元字符)。③重复或“闭包”,由元字符*****表示。
在这 3个运算中, *****优先权最高,连结其次,| 最末
期中补天
my ideas
3月4日

基本要求是利用一个decoder去完成k-net分割任务和detr3D的3D探测任务
首先找相似点,对于图像的特征提取部分,k-net与detr3D共用;后面k-net使用kernel进行迭代,与instance/mask建立起映射;detr使用query进行迭代,与reference point建立起映射;后面迭代的过程依赖于网络实现。kernel和query都是比较稀疏的?
怎么结合?
- 继承k-net,kernel也负责产生reference point?多视角怎么处理?
- 继承k-net,不同图像中的统一物体的mask上采样得到detr3D的feature,来做3D探测。我觉得可行性是有的,而且能很好的结合多视角的信息,而且detr最后依旧是回到了图像上能体现bounding box区域信息的特征提取上,而车的mask就包含了这个信息。我觉得值得一试
- 继承detr3D,query原本输出的是点,现在输出mask?再拿mask做3D探测?和第二点类似
- 两者都要?还没想好
更远的胡思乱想:
- 车、道路的运动时连续的,时序信息能辅助分析,比如连续两帧图像,在采样时间够短的情况下有理由认为同一辆车在两张图片中的位置使相近的(在这辆车没有跑出视野之前,不过是环视相机的全景图,不知道实际怎么样),怎么利用历史信息再说。但利用好了应该能简化运算,提高实时性
- 其实时序信息不仅仅能帮助目标检测,也能预测目标运行的方向,大致的速度?(如果有距离度量参数的话)。因为物体不可能瞬移,这是一个比较强的约束
- 车道线还没想好
4月11日
1.关于结合,可以采用k-net的思想,为detr3d最终采样到的local feature预测出一个mask,最后分割和检测任务都统一成预测kernel,kernel再分别与图像做卷积,全景分割的kernel卷积后得到的是分割的mask,而检测任务的kernel卷积得到的是检测的local feature,最后再用local feature去预测3维空间中的anchor box
潜在问题:
- detr3D最终利用local feature预测3维空间中anchor box的机理何在?输入和输出之间的联系不够紧密,我觉得这种方式未必是最好的方式,依赖这种结构不一定能做到最优
- 分割问题注重的是语义信息,检测问题注重的是位置信息。虽然实例分割和检测任务有相关性,但在新的框架下这两者共享多少参数?有多少关联性,位置信息和语义信息怎么单独体现还是个问题
2.Loop-attention机制,基于环视相机的cross attention集成体
6个环视相机,那就做六次类似的cross attention,每个attention的输出作为下一个相机的key/query(本相机的作为另一个),由此循环成一圈,为一个loop attention。可以利用最终的cross attention机制的输出结果去预测3D空间坐标?或者用最后6次的cross attention的输出连接在一起去预测3D空间坐标?或者用最后6次cross attention的输出结果去做应相机拍摄的图片的分割任务?
我认为loop attention的潜力:
- 是一种结合多尺度、空间信息的方式。既可以作为encoder,在多视角下提取空间的位置、语义信息,使用的时候需要将一个视角到另一个视角的变换矩阵一同输出。也可以作为decoder,类似cross attention的功能,但是能直接利用相邻视角相机、间接利用其它视角相机的信息。
- 联想到detr3D的query的做法,detr3D的query预测的是reference point,再将reference point格局变换矩阵映射回各个环视相机拍摄的图像上。这是一种多尺度信息的利用方法,但是我认为缺点很明显,一个是利用稀疏的点来关联视角这种高纬度的视觉信息是对空间一致性的一种浪费,没有很好挖掘视角之间的联系;其次,reference point不一定在每个相机中都有映射的点。但是两个相邻的环视相机肯定有交叉的地方。可以好好挖掘这部分的使用方法。
可以再拓展的地方:
- 与mask联系起来,相邻环视相机只提供与下一个相机同时看到的物体(利用mask做到),能加速
潜在弱点:
- 很明显,太慢了,在6倍计算量的基础上即使有mask做加速也显得慢
- 剩下的没做实验,不好说
等之后做实验验证想法吧,具体能不能work看实验结果
论文学习-Detr3D
一、任务概要与方法简述
1.概要
利用多相机多视角拍摄的图像做3D目标检测,也需要输出3D空间中的信息
目前很多工作都是直接使用2D目标检测问题的框架,从单目图像中估计3D bounding boxes,而没有考虑到3D场景结构或传感器信息。所以这些方法需要使用post-process来结合不同相机图像预测的bounding box以及剔除redundant boxes。
或者根据2D的特征信息利用depth prediction network做3D目标检测,或者做3D重建去达到类似激光雷达传感器获得的作用,随后再用3D信息做目标检测。这类方法的问题主要是重建3D场景或者恢复深度信息时的误差。
2.方法
- starts from a sparse set of object priors, shared across the dataset and learned end-to-end
- Back-project a set of reference points decoded from object priors to each camera and fetch the corresponding image features extracted by a ResNet backbone
- The features collected from the image features of the reference points then interact with each other through a multi-head self-attention layer
- After a series of self-attention layers, we read off bounding box parameters from every layer and use a set-to-set loss inspired by DETR to evaluate performance
二、做法细节
输入:K个相机采样的图像,相机参数,透视矩阵,ground-truth bounding boxes B与对应的categorical labels.Bounding box包含参数有:position,size,heading angle and velocity in birds-eye view(BEV)
输出:预测包含上述参数的bounding box与类别
1.特征提取
使用ResNet与FPN从输出图像中提取得到四组features, F1,F2,F3,F4,每一组特征都是不同level的特征用于提供探测不同大小的物体所需要的的信息
2.Detection Head
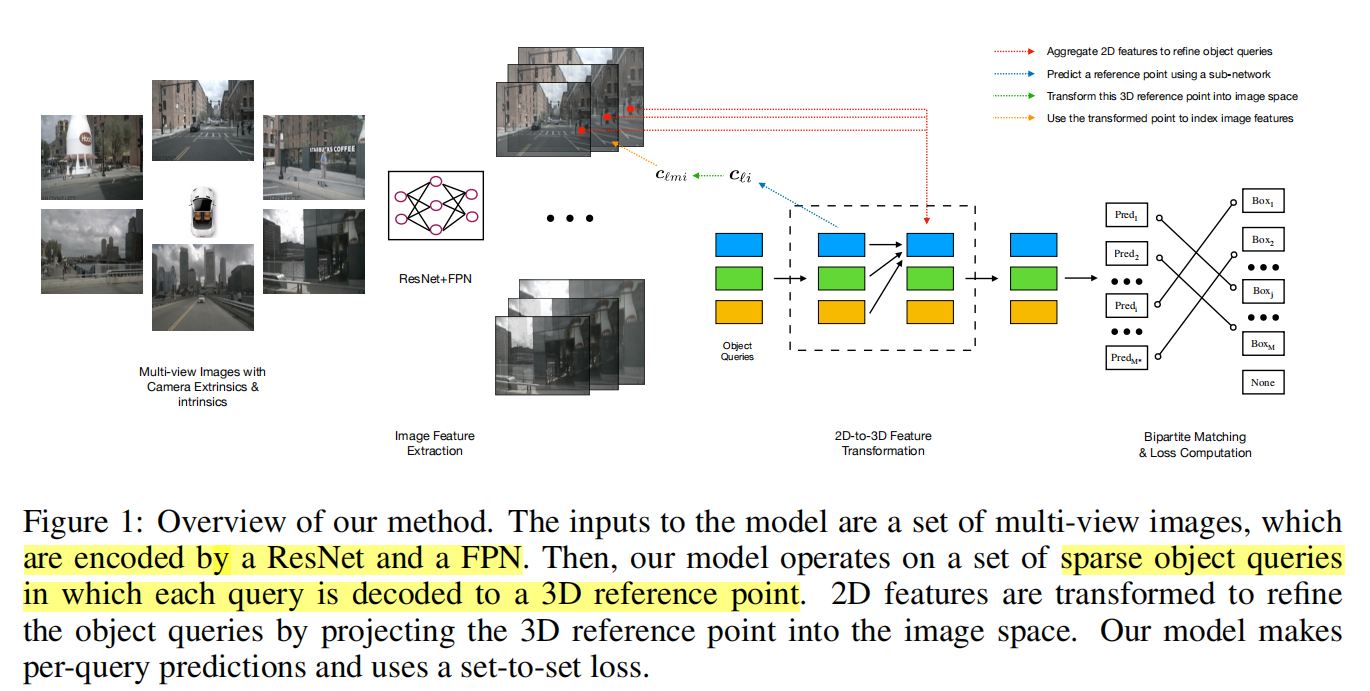
采取迭代方式,用L层layers去估计bounding boxes,以下步骤:
- predict a set of bounding box centers associated with object queries;
- project these centers into all the feature maps using the camera transformation matrices;
- sample features via bilinear interpolation and incorporate them into object queries;
- describe object interactions using multi-head attention.
先利用一个神经网络作为decoder生成reference point
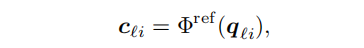
将坐标变成其次坐标并利用不同相机的转化矩阵将reference point的坐标利用透视矩阵做变换,考虑到不同level的feature maps的影响需要做归一化。

再利用双线性插值采样feature
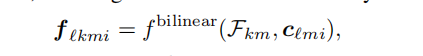
但是不是每个reference point都被被每个相机所采集,所以需要使用sigma来判断是都reference point被投影出了图像平面,最终的feature与下一层的object query由下述公式获取
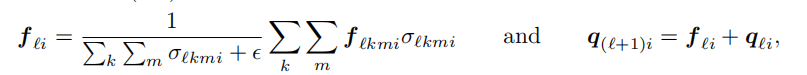
最后对每个object query,使用两个神经网络预测bounding box与类别
对迭代过程中每层都会预测,并计算loss来训练网络,但只会取最后一次的结果作为输出
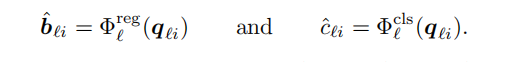
3.Loss
很显然loss源于两个因素,class prediction与bounding box parameters prediction
需要注意预测出的bounding box与ground box的数目不同,预测的往往更多,需要做padding
三、思考
1.首先肯定不能直接做3D重建再利用3D信息来做objection,因为误差是会传递的,而且这两个问题虽然逻辑上有一致性但它们的loss没有明显的正相关性,而且3D重建的error与loss难以控制。
特斯拉的做法:先直接将相机标定信息作为一个vector一起作为输入;之后又改为用一个变换矩阵对输入的每张图像做一次处理
我觉得可以学习特斯拉的做法,这篇paper看下来对于不用像机之间的联系是将inference point通过透视变换投影到原来的图像平面上,我感觉多视角的信息还是没有很好的结合在一起
2.这篇论文的流程:神经网络作为encoder提取特征–>>object queires作为decoder生成对应的inference point的3D坐标–>>根据相机矩阵映射会图像平面–>>双线性插值提取局部特征–>>利用局部特征用网络去预测box和category
转了一圈最终落脚点还是在图像信息上,3D坐标的计算也是个黑箱,哎,不是很懂。只是感觉对于3D的高纬度信息的产生和利用有点少。